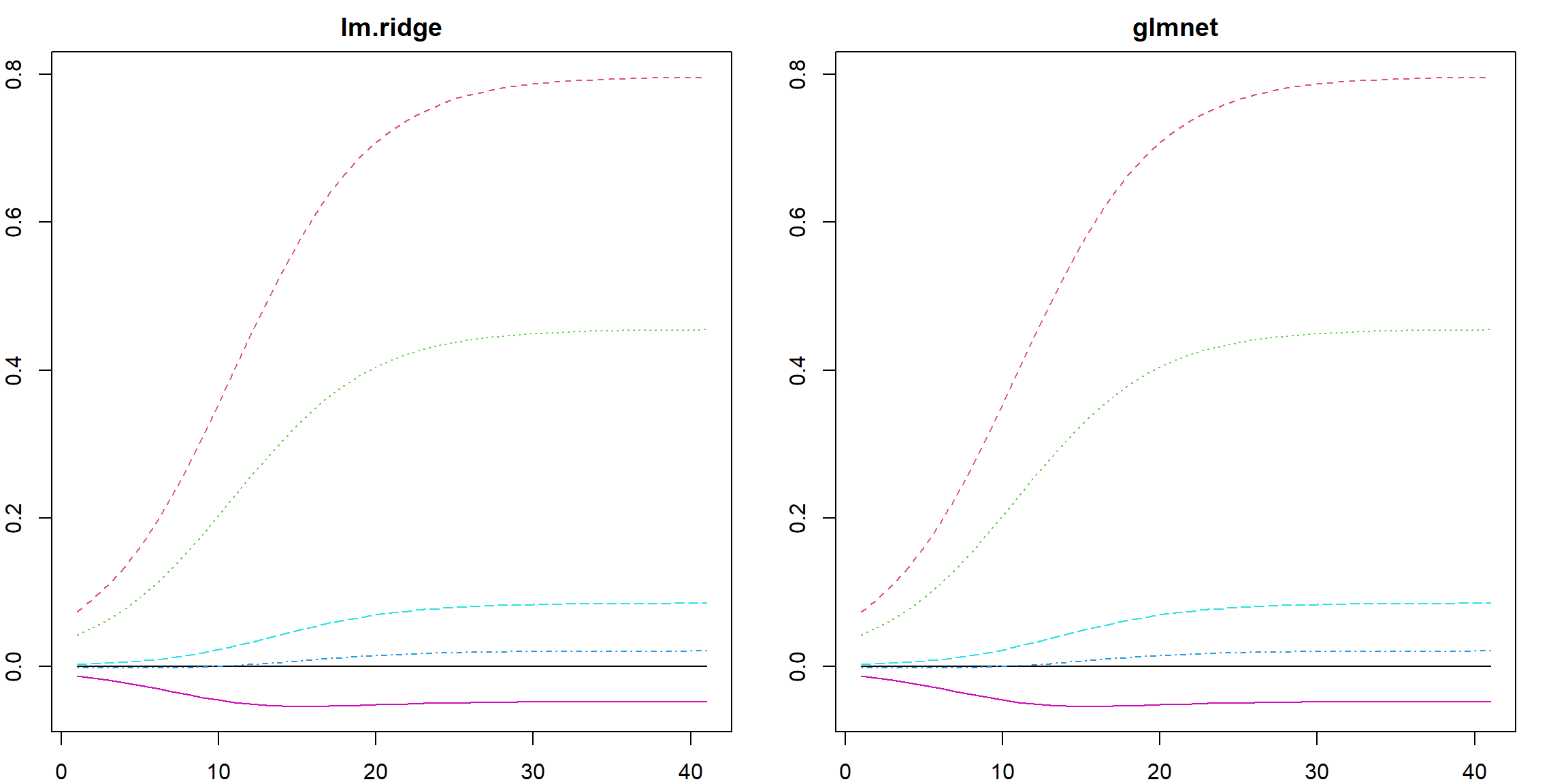Chapter 7 Ridge Regression
Ridge regression was proposed by Hoerl and Kennard (1970), but is also a special case of Tikhonov regularization. The essential idea is very simple: Knowing that the ordinary least squares (OLS) solution is not unique in an ill-posed problem, i.e., \(\mathbf{X}^\text{T}\mathbf{X}\) is not invertible, a ridge regression adds a ridge (diagonal matrix) on \(\mathbf{X}^\text{T}\mathbf{X}\):
\[\widehat{\boldsymbol{\beta}}^\text{ridge} = (\mathbf{X}^\text{T}\mathbf{X}+ n \lambda \mathbf{I})^{-1} \mathbf{X}^\text{T}\mathbf{y},\] It provides a solution of linear regression when multicollinearity happens, especially when the number of variables is larger than the sample size. Alternatively, this is also the solution of a regularized least square estimator. We add an \(\ell_2\) penalty to the residual sum of squares, i.e.,
\[ \begin{align} \widehat{\boldsymbol{\beta}}^\text{ridge} =& \arg\min_{\boldsymbol{\beta}} (\mathbf{y}- \mathbf{X}\boldsymbol{\beta})^\text{T}(\mathbf{y}- \mathbf{X}\boldsymbol{\beta}) + n \lambda \lVert\boldsymbol{\beta}\rVert_2^2\\ =& \arg\min_{\boldsymbol{\beta}} \frac{1}{n} \sum_{i=1}^n (y_i - x_i^\text{T}\boldsymbol{\beta})^2 + \lambda \sum_{j=1}^p \beta_j^2, \end{align} \]
for some penalty \(\lambda > 0\). Another approach that leads to the ridge regression is a constraint on the \(\ell_2\) norm of the parameters, which will be introduced in the next Chapter. Ridge regression is used extensively in genetic analyses to address “small-\(n\)-large-\(p\)” problems. We will start with a motivation example and then discuss the bias-variance trade-off issue.
7.1 Motivation: Correlated Variables and Convexity
Ridge regression has many advantages. Most notably, it can address highly correlated variables. From an optimization point of view, having highly correlated variables means that the objective function (\(\ell_2\) loss) becomes “flat” along certain directions in the parameter domain. This can be seen from the following example, where the true parameters are both \(1\) while the estimated parameters concludes almost all effects to the first variable. You can change different seed to observe the variability of these parameter estimates and notice that they are quite large. Instead, if we fit a ridge regression, the parameter estimates are relatively stable.
library(MASS)
set.seed(2)
n = 30
# create highly correlated variables and a linear model
X = mvrnorm(n, c(0, 0), matrix(c(1,0.99, 0.99, 1), 2,2))
y = rnorm(n, mean = X[,1] + X[,2])
# compare parameter estimates
summary(lm(y~X-1))$coef
## Estimate Std. Error t value Pr(>|t|)
## X1 1.8461255 1.294541 1.42608527 0.1648987
## X2 0.0990278 1.321283 0.07494822 0.9407888
# note that the true parameters are all 1's
# Be careful that the `lambda` parameter in lm.ridge is our (n*lambda)
lm.ridge(y~X-1, lambda=5)
## X1 X2
## 0.9413221 0.8693253The variance of both \(\beta_1\) and \(\beta_2\) are quite large. This is expected because we know from linear regression that the variance of \(\widehat{\boldsymbol{\beta}}\) is \(\sigma^2 (\mathbf{X}^\text{T}\mathbf{X})^{-1}\). However, since the columns of \(\mathbf{X}\) are highly correlated, the smallest eigenvalue of \(\mathbf{X}^\text{T}\mathbf{X}\) is close to 0, making the largest eigenvalue of \((\mathbf{X}^\text{T}\mathbf{X})^{-1}\) very large. This can also be interpreted through an optimization point of view. The objective function for an OLS estimator is demonstrated in the following.
beta1 <- seq(0, 3, 0.005)
beta2 <- seq(-1, 2, 0.005)
allbeta <- data.matrix(expand.grid(beta1, beta2))
rss <- matrix(apply(allbeta, 1, function(b, X, y) sum((y - X %*% b)^2), X, y),
length(beta1), length(beta2))
# quantile levels for drawing contour
quanlvl = c(0.01, 0.025, 0.05, 0.2, 0.5, 0.75)
# plot the contour
contour(beta1, beta2, rss, levels = quantile(rss, quanlvl))
box()
# the truth
points(1, 1, pch = 19, col = "red", cex = 2)
# the data
betahat <- coef(lm(y~X-1))
points(betahat[1], betahat[2], pch = 19, col = "blue", cex = 2)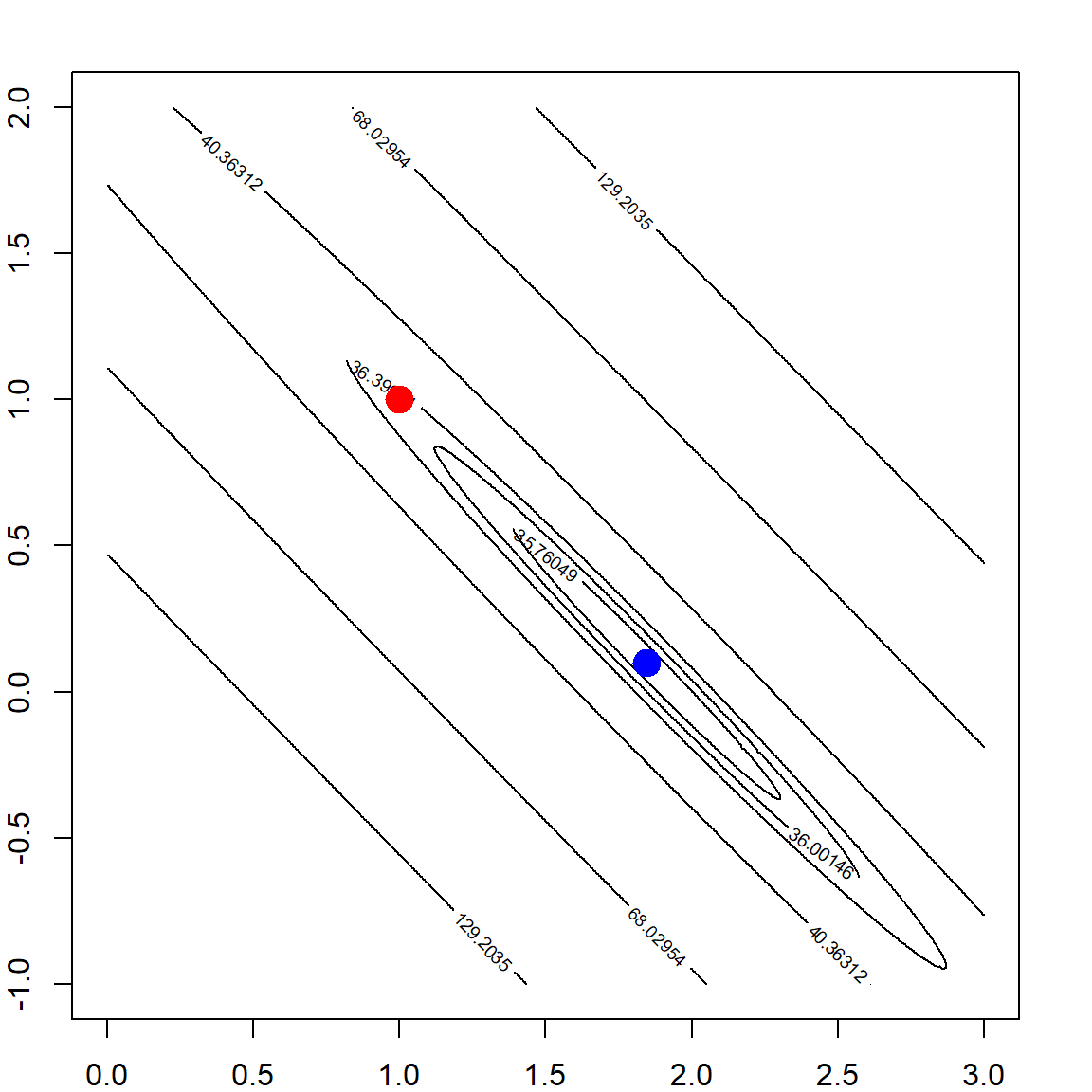
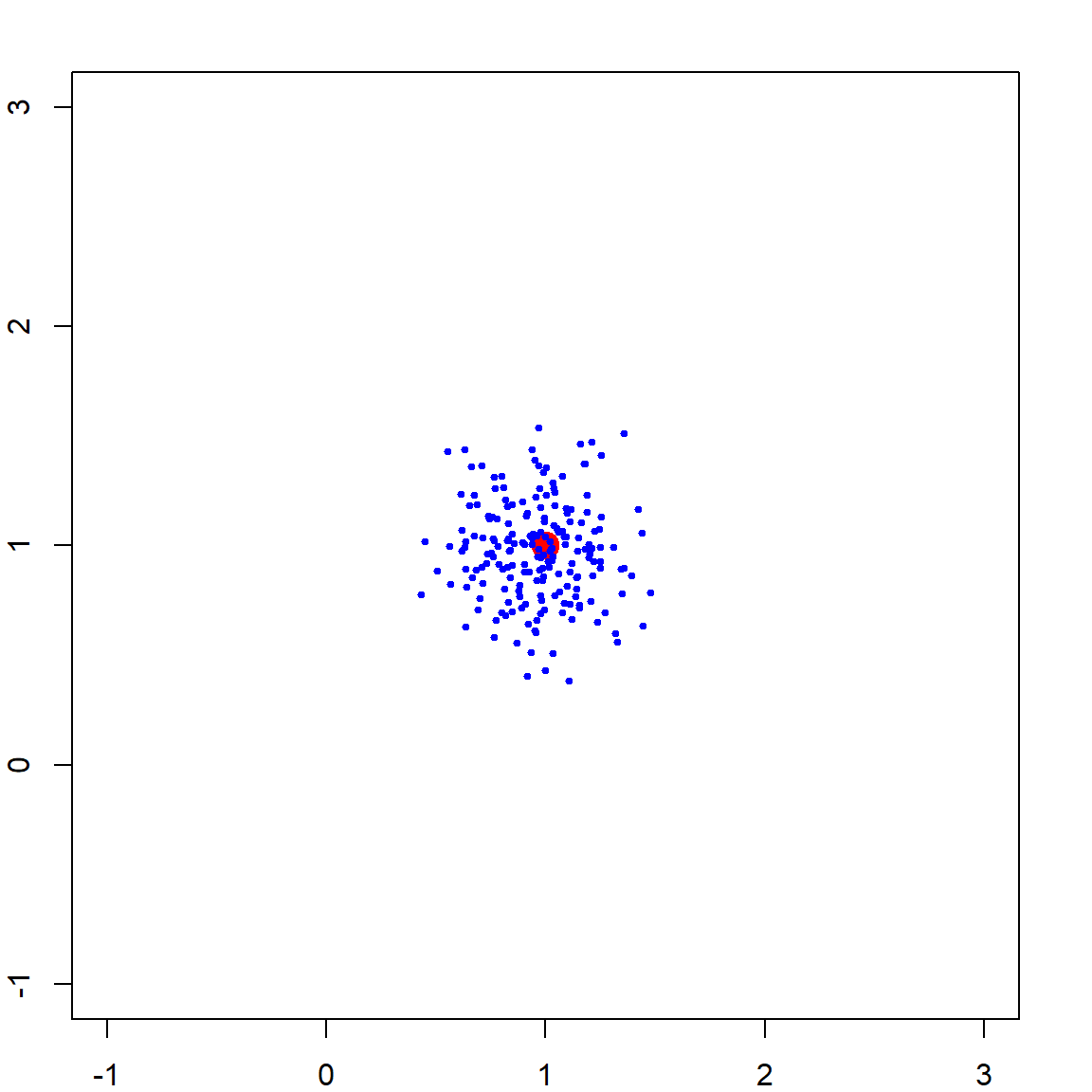
Over many simulation runs, the solution lies around the line of \(\beta_1 + \beta_2 = 2\).
# the truth
plot(NA, NA, xlim = c(-1, 3), ylim = c(-1, 3))
points(1, 1, pch = 19, col = "red", cex = 2)
# generate many datasets in a simulation
for (i in 1:200)
{
X = mvrnorm(n, c(0, 0), matrix(c(1,0.99, 0.99, 1), 2,2))
y = rnorm(n, mean = X[,1] + X[,2])
betahat <- solve(t(X) %*% X) %*% t(X) %*% y
points(betahat[1], betahat[2], pch = 19, col = "blue", cex = 0.5)
}
7.2 Ridge Penalty and the Reduced Variation
If we add a ridge regression penalty, the contour is forced to be more convex due to the added eigenvalues on \(\mathbf{X}^\mathbf{X}\), making the eignvalues of \((\mathbf{X}^\mathbf{X})^{-1}\) smaller. Here is a plot of the Ridge \(\ell_2\) penalty.
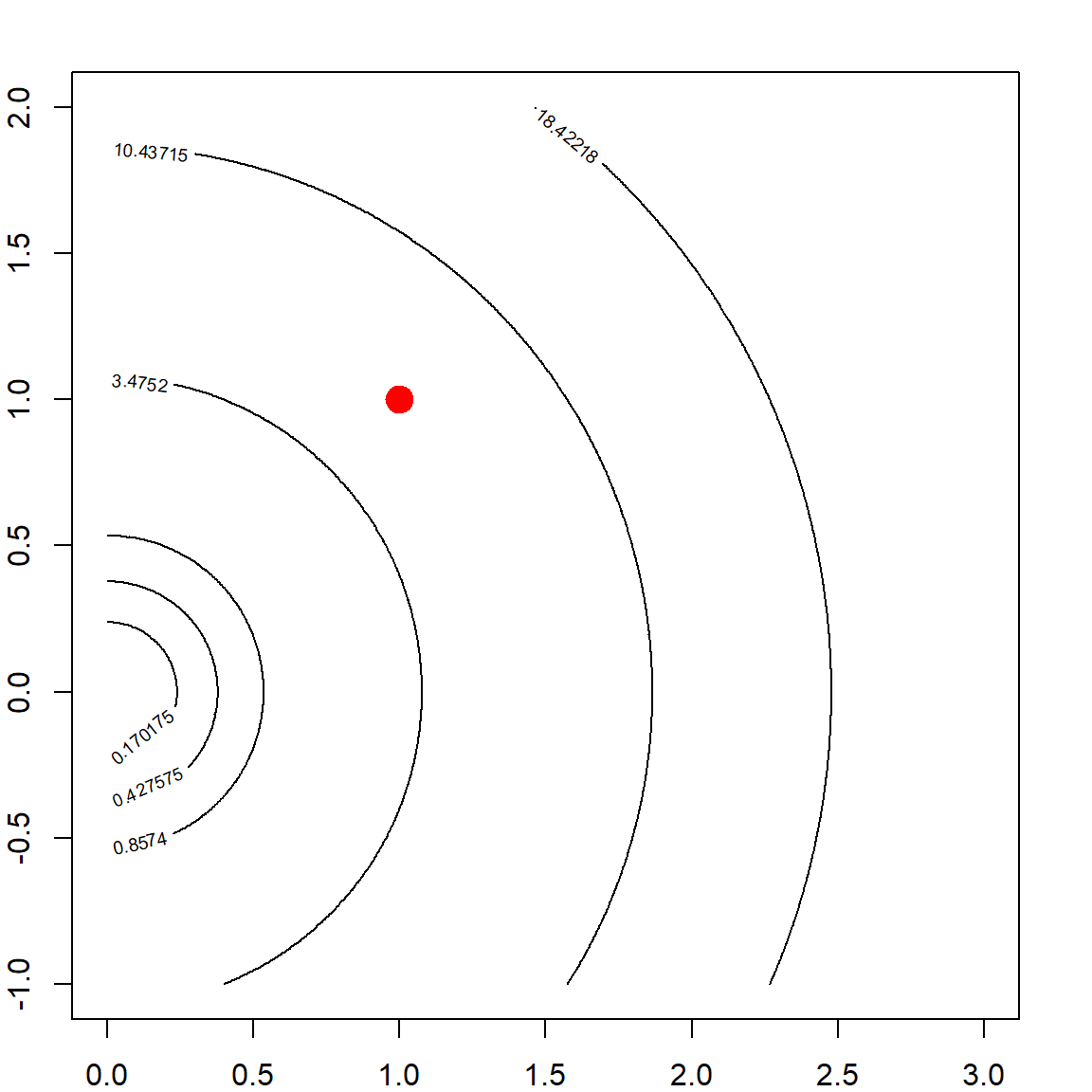
Hence, by adding this to the OLS objective function, the solution is more stable. This may be interpreted in several different ways such as: 1) the objective function is more convex; 2) the variance of the estimator is smaller. However, this causes some bias too. Choosing the tuning parameter is a balance of the bias-variance trade-off, which will be discussed in the following.
par(mfrow=c(1, 2))
# adding a L2 penalty to the objective function
rss <- matrix(apply(allbeta, 1, function(b, X, y) sum((y - X %*% b)^2) + b %*% b, X, y),
length(beta1), length(beta2))
# the ridge solution
bh = solve(t(X) %*% X + diag(2)) %*% t(X) %*% y
contour(beta1, beta2, rss, levels = quantile(rss, quanlvl))
points(1, 1, pch = 19, col = "red", cex = 2)
points(bh[1], bh[2], pch = 19, col = "blue", cex = 2)
box()
# adding a larger penalty
rss <- matrix(apply(allbeta, 1, function(b, X, y) sum((y - X %*% b)^2) + 10*b %*% b, X, y),
length(beta1), length(beta2))
bh = solve(t(X) %*% X + 10*diag(2)) %*% t(X) %*% y
# the ridge solution
contour(beta1, beta2, rss, levels = quantile(rss, quanlvl))
points(1, 1, pch = 19, col = "red", cex = 2)
points(bh[1], bh[2], pch = 19, col = "blue", cex = 2)
box()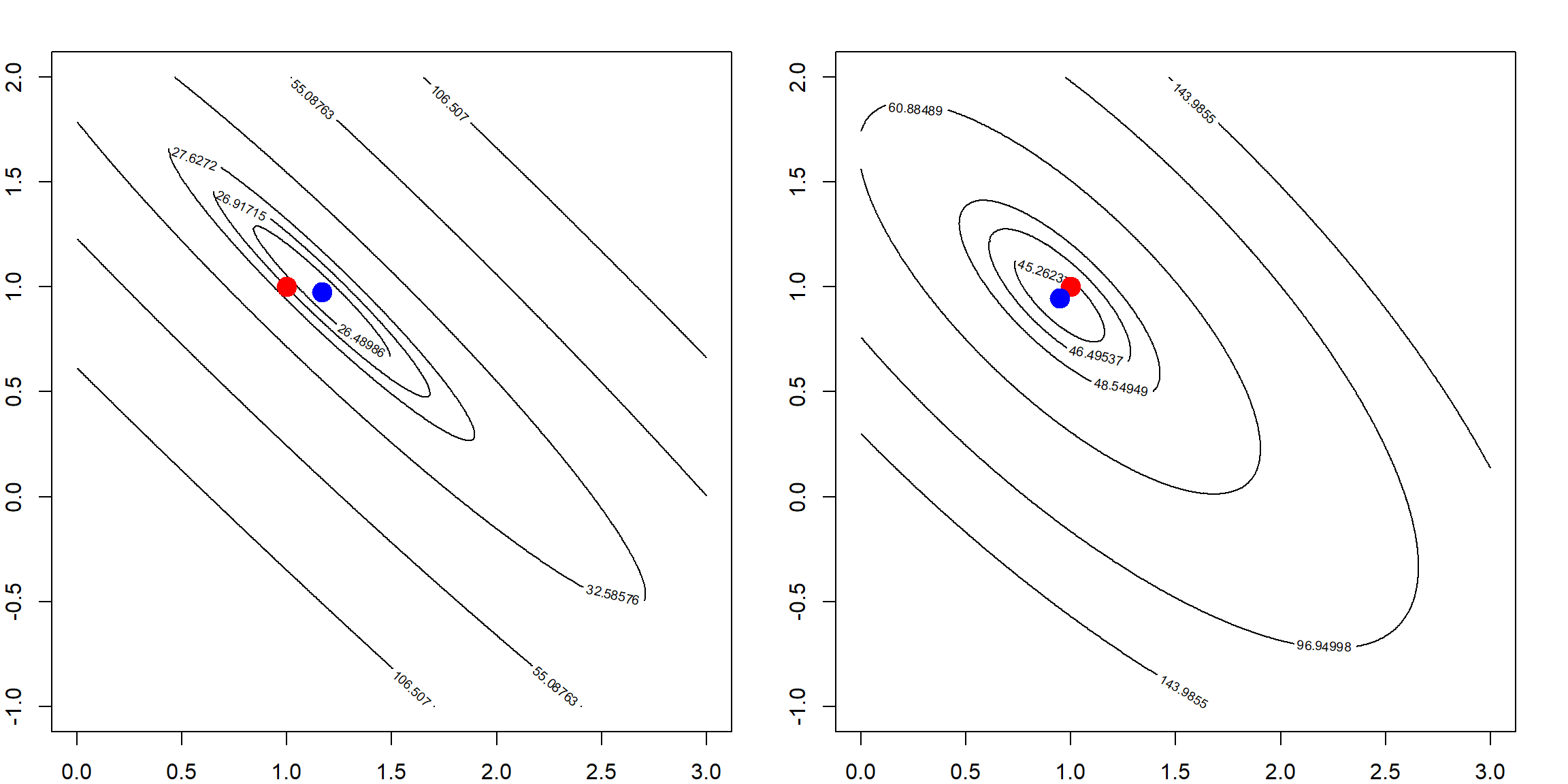
We can check the ridge solution over many simulation runs
par(mfrow=c(1, 1))
# the truth
plot(NA, NA, xlim = c(-1, 3), ylim = c(-1, 3))
points(1, 1, pch = 19, col = "red", cex = 2)
# generate many datasets in a simulation
for (i in 1:200)
{
X = mvrnorm(n, c(0, 0), matrix(c(1,0.99, 0.99, 1), 2,2))
y = rnorm(n, mean = X[,1] + X[,2])
# betahat <- solve(t(X) %*% X + 2*diag(2)) %*% t(X) %*% y
betahat <- lm.ridge(y ~ X - 1, lambda = 2)$coef
points(betahat[1], betahat[2], pch = 19, col = "blue", cex = 0.5)
}
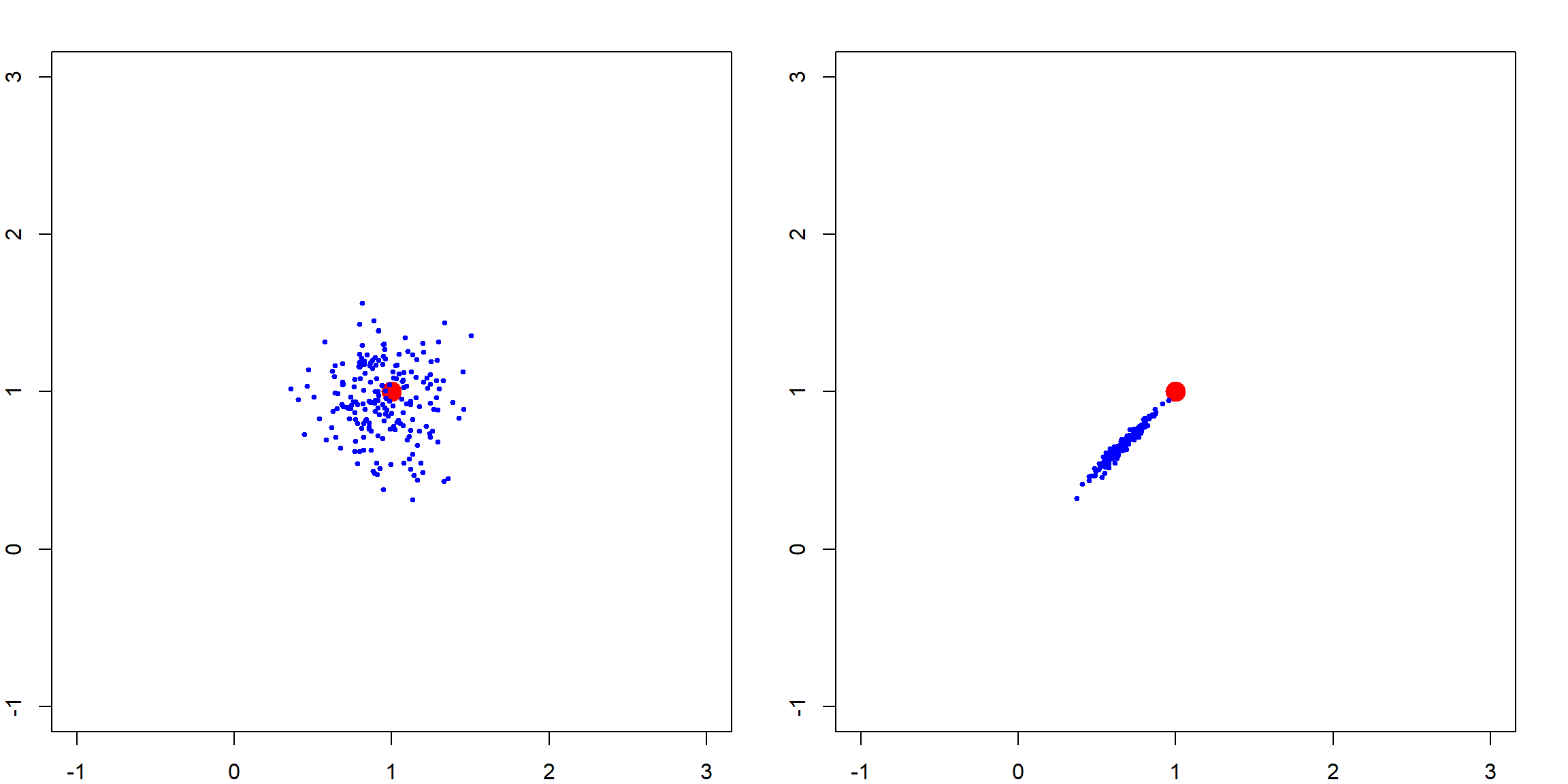
This effect is gradually changing as we increase the penalty level. The following simulation shows how the variation of \(\boldsymbol{\beta}\) changes. We show this with two penalty values, and see how the estimated parameters are away from the truth.
par(mfrow = c(1, 2))
# small penalty
plot(NA, NA, xlim = c(-1, 3), ylim = c(-1, 3))
points(1, 1, pch = 19, col = "red", cex = 2)
# generate many datasets in a simulation
for (i in 1:200)
{
X = mvrnorm(n, c(0, 0), matrix(c(1,0.99, 0.99, 1), 2,2))
y = rnorm(n, mean = X[,1] + X[,2])
betahat <- lm.ridge(y ~ X - 1, lambda = 2)$coef
points(betahat[1], betahat[2], pch = 19, col = "blue", cex = 0.5)
}
# large penalty
plot(NA, NA, xlim = c(-1, 3), ylim = c(-1, 3))
points(1, 1, pch = 19, col = "red", cex = 2)
# generate many datasets in a simulation
for (i in 1:200)
{
X = mvrnorm(n, c(0, 0), matrix(c(1,0.99, 0.99, 1), 2,2))
y = rnorm(n, mean = X[,1] + X[,2])
# betahat <- solve(t(X) %*% X + 30*diag(2)) %*% t(X) %*% y
betahat <- lm.ridge(y ~ X - 1, lambda = 30)$coef
points(betahat[1], betahat[2], pch = 19, col = "blue", cex = 0.5)
}
7.3 Bias and Variance of Ridge Regression
We can set a relationship between Ridge and OLS, assuming that the OLS estimator exist.
\[\begin{align} \widehat{\boldsymbol{\beta}}^\text{ridge} =& (\mathbf{X}^\text{T}\mathbf{X}+ n\lambda \mathbf{I})^{-1} \mathbf{X}^\text{T}\mathbf{y}\\ =& (\mathbf{X}^\text{T}\mathbf{X}+ n\lambda \mathbf{I})^{-1} (\mathbf{X}^\text{T}\mathbf{X}) \color{OrangeRed}{(\mathbf{X}^\text{T}\mathbf{X})^{-1} \mathbf{X}^\text{T}\mathbf{y}}\\ =& (\mathbf{X}^\text{T}\mathbf{X}+ n\lambda \mathbf{I})^{-1} (\mathbf{X}^\text{T}\mathbf{X}) \color{OrangeRed}{\widehat{\boldsymbol{\beta}}^\text{ols}} \end{align}\]
This leads to a biased estimator (since the OLS estimator is unbiased) if we use any nonzero \(\lambda\).
- As \(\lambda \rightarrow 0\), the ridge solution is eventually the same as OLS
- As \(\lambda \rightarrow \infty\), \(\widehat{\boldsymbol{\beta}}^\text{ridge} \rightarrow 0\)
It can be easier to analyze a case with \(\mathbf{X}^\text{T}\mathbf{X}= n \mathbf{I}\), i.e, with standardized and orthogonal columns in \(\mathbf{X}\). Note that in this case, each \(\beta_j^{\text{ols}}\) is just the projection of \(\mathbf{y}\) onto \(\mathbf{x}_j\), the \(j\)th column of the design matrix. We also have
\[\begin{align} \widehat{\boldsymbol{\beta}}^\text{ridge} =& (\mathbf{X}^\text{T}\mathbf{X}+ n\lambda \mathbf{I})^{-1} (\mathbf{X}^\text{T}\mathbf{X}) \widehat{\boldsymbol{\beta}}^\text{ols}\\ =& (\mathbf{I}+ \lambda \mathbf{I})^{-1}\widehat{\boldsymbol{\beta}}^\text{ols}\\ =& (1 + \lambda)^{-1} \widehat{\boldsymbol{\beta}}^\text{ols}\\ \Longrightarrow \widehat{\beta}_j^{\text{ridge}} =& \frac{1}{1 + \lambda} \widehat{\beta}_j^\text{ols} \end{align}\]
Then in this case, the bias and variance of the ridge estimator can be explicitly expressed. Here for the bias term, we assume that the OLS estimator is unbiased, i.e., \(\text{E}(\widehat{\beta}_j^\text{ols}) = \beta_j\). Then
- \(\text{Bias}(\widehat{\beta}_j^{\text{ridge}}) = E[\widehat{\beta}_j^{\text{ridge}} - \beta_j] = \frac{-\lambda}{1 + \lambda} \beta_j\) (not zero)
- \(\text{Var}(\widehat{\beta}_j^{\text{ridge}}) = \frac{1}{(1 + \lambda)^2} \text{Var}(\widehat{\beta}_j^\text{ols})\) (reduced from OLS)
Of course, we can ask the question: is it worth it? We could proceed with a simple analysis of the MSE of \(\beta\) (dropping \(j\) for simplicity). Note that this is also the MSE for predicting the expected value of a subject (\(x^\text{T}\beta\)) with covariate \(x = 1\).
\[\begin{align} \text{MSE}(\beta) &= \text{E}(\widehat{\beta} - \beta)^2 \\ &= \text{E}[\widehat{\beta} - \text{E}(\widehat{\beta})]^2 + \text{E}[\widehat{\beta} - \beta]^2 \\ &= \text{E}[\widehat{\beta} - \text{E}(\widehat{\beta})]^2 + 0 + [\text{E}(\widehat{\beta}) - \beta]^2 \\ &= \text{Var}(\widehat{\beta}) + \text{Bias}^2. \end{align}\]
This bias-variance breakdown formula will appear multiple times in later lectures. Now, plugging in the results developed earlier based on the orthogonal design matrix, and investigate the derivative of the MSE of the Ridge estimator, we have
\[\begin{align} \frac{\partial \text{MSE}(\widehat{\beta}^\text{ridge})}{ \partial \lambda} =& \frac{\partial}{\partial \lambda} \left[ \frac{1}{(1+\lambda)^2} \text{Var}(\widehat{\beta}^\text{ols}) + \frac{\lambda^2}{(1 + \lambda)^2} \beta^2 \right] \\ =& \frac{2}{(1+\lambda)^3} \left[ \lambda \beta^2 - \text{Var}(\widehat{\beta}^\text{ols}) \right] \end{align}\]
Note that when the derivative is negative, increasing \(\lambda\) would decrease the MSE. This implies that we can reduce the MSE by choosing a small \(\lambda\). However, we are not able to know the best choice of \(\lambda\) since the true \(\beta\) is unknown. One the other hand, the situation is much more involving when the columns in \(\mathbf{X}\) are not orthogonal. The following analysis helps to understand a non-orthogonal case. It is essentially re-organizing the columns of \(\mathbf{X}\) into its principal components so that they are still orthogonal.
Let’s first take a singular value decomposition (SVD) of \(\mathbf{X}\), with \(\mathbf{X}= \mathbf{U}\mathbf{D}\mathbf{V}^\text{T}\), then the columns in \(\mathbf{U}\) form an orthogonal basis and columns in \(\mathbf{U}\mathbf{D}\) are the principal components and \(\mathbf{V}\) defines the principal directions. In addition, we have \(n \widehat{\boldsymbol \Sigma} = \mathbf{X}^\text{T}\mathbf{X}= \mathbf{V}\mathbf{D}^2 \mathbf{V}^\text{T}\). Assuming that \(p < n\), and \(\mathbf{X}\) has full column ranks, then the Ridge estimator fitted \(\mathbf{y}\) value can be decomposed as
\[\begin{align} \widehat{\mathbf{y}}^\text{ridge} =& \mathbf{X}\widehat{\beta}^\text{ridge} \\ =& \mathbf{X}(\mathbf{X}^\text{T}\mathbf{X}+ n \lambda)^{-1} \mathbf{X}^\text{T}\mathbf{y}\\ =& \mathbf{U}\mathbf{D}\mathbf{V}^\text{T}( \mathbf{V}\mathbf{D}^2 \mathbf{V}^\text{T}+ n \lambda \mathbf{V}\mathbf{V}^\text{T})^{-1} \mathbf{V}\mathbf{D}\mathbf{U}^\text{T}\mathbf{y}\\ =& \mathbf{U}\mathbf{D}^2 (n \lambda + \mathbf{D}^2)^{-1} \mathbf{U}^\text{T}\mathbf{y}\\ =& \sum_{j = 1}^p \mathbf{u}_j \left( \frac{d_j^2}{n \lambda + d_j^2} \mathbf{u}_j^\text{T}\mathbf{y}\right), \end{align}\]
where \(d_j\) is the \(j\)th eigenvalue of the PCA. Hence, the Ridge regression fitted value can be understood as
- Perform PCA of \(\mathbf{X}\)
- Project \(\mathbf{y}\) onto the PCs
- Shrink the projection \(\mathbf{u}_j^\text{T}\mathbf{y}\) by the factor \(d_j^2 / (n \lambda + d_j^2)\)
- Reassemble the PCs using all the shrunken length
Hence, the bias-variance notion can be understood as the trade-off on these derived directions \(\mathbf{u}_j\) and their corresponding parameters \(\mathbf{u}_j^\text{T}\mathbf{y}\).
7.4 Degrees of Freedom
We know that for a linear model, the degrees of freedom (DF) is simply the number of parameters used. There is a formal definition, using
\[\begin{align} \text{DF}(\widehat{f}) =& \frac{1}{\sigma^2} \sum_{i = 1}^n \text{Cov}(\widehat{y}_i, y_i)\\ =& \frac{1}{\sigma^2} \text{Trace}[\text{Cov}(\widehat{\mathbf{y}}, \mathbf{y})] \end{align}\]
We can check that for a linear regression (assuming the intercept is already included in \(\mathbf{X}\)), the DF is
\[\begin{align} \frac{1}{\sigma^2} \text{Trace}[\text{Cov}(\widehat{\mathbf{y}}^\text{ols}, \mathbf{y})] =& \frac{1}{\sigma^2} \text{Trace}[\text{Cov}(\mathbf{X}(\mathbf{X}^\text{T}\mathbf{X})^{-1} \mathbf{X}^\text{T}\mathbf{y}, \mathbf{y})] \\ =& \text{Trace}(\mathbf{X}(\mathbf{X}^\text{T}\mathbf{X})^{-1} \mathbf{X}^\text{T}) \\ =& \text{Trace}(\mathbf{I}_{p\times p})\\ =& p \end{align}\]
For the Ridge regression, we can perform the same analysis on ridge regression.
\[\begin{align} \frac{1}{\sigma^2} \text{Trace}[\text{Cov}(\widehat{\mathbf{y}}^\text{ridge}, \mathbf{y})] =& \frac{1}{\sigma^2} \text{Trace}[\text{Cov}(\mathbf{X}(\mathbf{X}^\text{T}\mathbf{X}+ n \lambda \mathbf{I})^{-1} \mathbf{X}^\text{T}\mathbf{y}, \mathbf{y})] \\ =& \text{Trace}(\mathbf{X}(\mathbf{X}^\text{T}\mathbf{X}+ n \lambda \mathbf{I})^{-1} \mathbf{X}^\text{T}) \\ =& \text{Trace}(\mathbf{U}\mathbf{D}\mathbf{V}^\text{T}( \mathbf{V}\mathbf{D}^2 \mathbf{V}^\text{T}+ n \lambda \mathbf{V}\mathbf{V}^\text{T})^{-1} \mathbf{V}\mathbf{D}\mathbf{U}^\text{T})\\ =& \sum_{j = 1}^p \frac{d_j^2}{d_j^2 + n\lambda} \end{align}\]
Note that this is smaller than \(p\) as long as \(\lambda \neq 0\). This implies that the Ridge regression does not use the full potential of all \(p\) variables, since there is a risk of over-fitting.
7.5 Using the lm.ridge() function
We have seen how the lm.ridge() can be used to fit a Ridge regression. However, keep in mind that the lambda parameter used in the function actually specifies the \(n \lambda\) entirely we used in our notation. However, regardless, our goal is mainly to tune this parameter to achieve a good balance of bias-variance trade off. However, the difficulty here is to evaluate the performance without knowing the truth. Let’s first use a simulated example, in which we do know the truth and then introduce the cross-validation approach for real data where we do not know the truth.
We use the prostate cancer data prostate from the ElemStatLearn package. The dataset contains 8 explanatory variables and one outcome lpsa, the log prostate-specific antigen value.
# ElemStatLearn is currently archived, install a previous version
# library(devtools)
# install_version("ElemStatLearn", version = "2015.6.26", repos = "http://cran.r-project.org")
library(ElemStatLearn)
head(prostate)
## lcavol lweight age lbph svi lcp gleason pgg45 lpsa train
## 1 -0.5798185 2.769459 50 -1.386294 0 -1.386294 6 0 -0.4307829 TRUE
## 2 -0.9942523 3.319626 58 -1.386294 0 -1.386294 6 0 -0.1625189 TRUE
## 3 -0.5108256 2.691243 74 -1.386294 0 -1.386294 7 20 -0.1625189 TRUE
## 4 -1.2039728 3.282789 58 -1.386294 0 -1.386294 6 0 -0.1625189 TRUE
## 5 0.7514161 3.432373 62 -1.386294 0 -1.386294 6 0 0.3715636 TRUE
## 6 -1.0498221 3.228826 50 -1.386294 0 -1.386294 6 0 0.7654678 TRUE7.5.1 Scaling Issue
We can use lm.ridge() with a fixed \(\lambda\) value, as we have shown in the previous example. Its syntax is again similar to the lm() function, with an additional argument lambda. We can also compare that with our own code.
# lm.ridge function from the MASS package
lm.ridge(lpsa ~., data = prostate[, 1:9], lambda = 1)
## lcavol lweight age lbph svi lcp gleason
## 0.14716982 0.55209405 0.61998311 -0.02049376 0.09488234 0.74846397 -0.09399009 0.05227074
## pgg45
## 0.00424397
# using our own code
X = cbind(1, data.matrix(prostate[, 1:8]))
y = prostate[, 9]
solve(t(X) %*% X + diag(9)) %*% t(X) %*% y
## [,1]
## 0.07941225
## lcavol 0.55985143
## lweight 0.60398302
## age -0.01957258
## lbph 0.09395770
## svi 0.68809341
## lcp -0.08863685
## gleason 0.06288206
## pgg45 0.00416878However, they look different. This is because ridge regression has a scaling issue: it would shrink parameters differently if the corresponding covariates have different scales. This can be seen from our previous development of the SVD analysis. Since the shrinkage is the same for all \(d_j\)s, it would apply a larger shrinkage for small \(d_j\). A commonly used approach to deal with the scaling issue is to standardize all covariates such that they are treated the same way. In addition, we will also center both \(\mathbf{X}\) and \(\mathbf{y}\) before performing the ridge regression. An interesting consequence of centering is that we do not need the intercept anymore, since \(\mathbf{X}\boldsymbol{\beta}= \mathbf{0}\) for all \(\boldsymbol{\beta}\). One last point is that when performing scaling, lm.ridge() use the \(n\) factor instead of \(n-1\) when calculating the standard deviation. Hence, incorporating all these, we have
# perform centering and scaling
X = scale(data.matrix(prostate[, 1:8]), center = TRUE, scale = TRUE)
# use n instead of (n-1) for standardization
n = nrow(X)
X = X * sqrt(n / (n-1))
# center y but not scaling
y = scale(prostate[, 9], center = TRUE, scale = FALSE)
# getting the estimated parameter
mybeta = solve(t(X) %*% X + diag(8)) %*% t(X) %*% y
ridge.fit = lm.ridge(lpsa ~., data = prostate[, 1:9], lambda = 1)
# note that $coef obtains the coefficients internally from lm.ridge
# however coef() would transform these back to the original scale version
cbind(mybeta, ridge.fit$coef)
## [,1] [,2]
## lcavol 0.64734891 0.64734891
## lweight 0.26423507 0.26423507
## age -0.15178989 -0.15178989
## lbph 0.13694453 0.13694453
## svi 0.30825889 0.30825889
## lcp -0.13074243 -0.13074243
## gleason 0.03755141 0.03755141
## pgg45 0.11907848 0.119078487.5.2 Multiple \(\lambda\) values
Since we now face the problem of bias-variance trade-off, we can fit the model with multiple \(\lambda\) values and select the best. This can be done using the following code.
For each \(\lambda\), the coefficients of all variables are recorded. The plot shows how these coefficients change as a function of \(\lambda\). We can easily see that as \(\lambda\) becomes larger, the coefficients are shrunken towards 0. This is consistent with our understanding of the bias. On the very left hand size of the plot, the value of each parameter corresponds to the OLS result since no penalty is applied. Be careful that the coefficients of the fitted objects fit$coef are scaled by the standard deviation of the covariates. If you need the original scale, make sure to use coef(fit).
matplot(coef(fit)[, -1], type = "l", xlab = "Lambda", ylab = "Coefficients")
text(rep(50, 8), coef(fit)[1,-1], colnames(prostate)[1:8])
title("Prostate Cancer Data: Ridge Coefficients")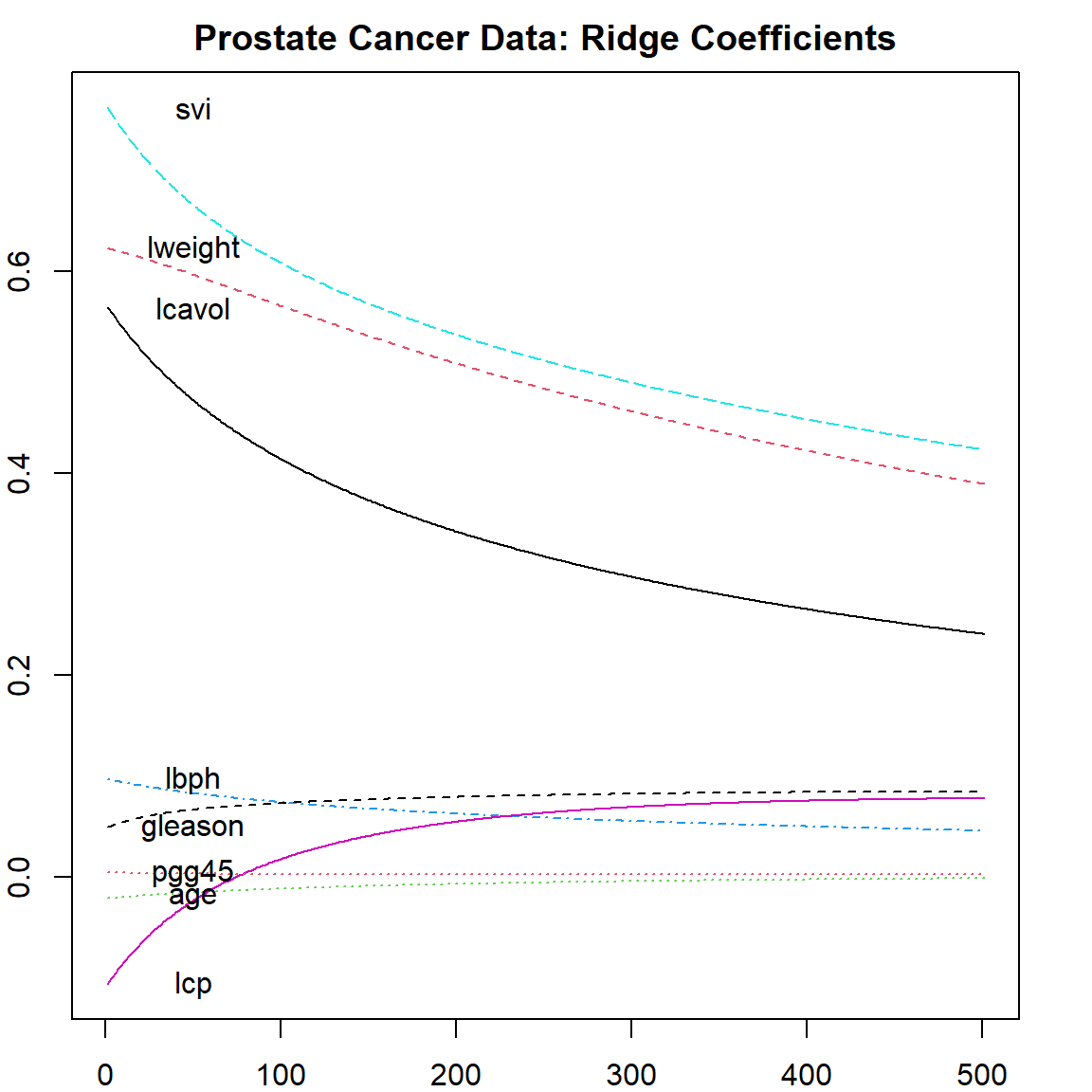
To select the best \(\lambda\) value, there can be several different methods. We will discuss two approaches among them: \(k\)-fold cross-validation and generalized cross-validation (GCV).
7.6 Cross-validation
Cross-validation (CV) is a technique to evaluate the performance of a model on an independent set of data. The essential idea is to separate out a subset of the data and do not use that part during the training, while using it for testing. We can then rotate to or sample a different subset as the testing data. Different cross-validation methods differs on the mechanisms of generating such testing data. \(K\)-fold cross-validation is probably the the most popular among them. The method works in the following steps:
- Randomly split the data into \(K\) equal portions
- For each \(k\) in \(1, \ldots, K\): use the \(k\)th portion as the testing data and the rest as training data, obtain the testing error
- Average all \(K\) testing errors
Here is a graphical demonstration of a \(10\)-fold CV:

There are also many other cross-validation procedures, for example, the Monte Carlo cross-validation randomly splits the data into training and testing (instead of fix \(K\) portions) each time and repeat the process as many times as we like. The benefit of such procedure is that if this is repeated enough times, the estimated testing error becomes fairly stable, and not affected much by the random mechanism. On the other hand, we can also repeat the entire \(K\)-fold CV process many times, then average the errors. This is also trying to reduced the influence of randomness.
7.7 Leave-one-out cross-validation
Regarding the randomness, the leave-one-out cross-validation is completely nonrandom. It is essentially the \(k\)-fold CV approach, but with \(k\) equal to \(n\), the sample size. A standard approach would require to re-fit the model \(n\) times, however, some linear algebra can show that there is an equivalent form using the “Hat” matrix when fitting a linear regression:
\[\begin{align} \text{CV}(n) =& \frac{1}{n}\sum_{i=1}^n (y_i - \widehat{y}_{[i]})^2\\ =& \frac{1}{n} \sum_{i=1}^n \left( \frac{y_i - \widehat{y}_i}{1 - \mathbf{H}_{ii}} \right)^2, \end{align}\] where \(\widehat{y}_{i}\) is the fitted value using the whole dataset, but \(\widehat{y}_{[i]}\) is the prediction of \(i\)th observation using the data without it when fitting the model. And \(\mathbf{H}_{ii}\) is the \(i\)th diagonal element of the hat matrix \(\mathbf{H}= \mathbf{X}(\mathbf{X}^\text{T}\mathbf{X})^{-1} \mathbf{X}\). The proof is essentially an application of the Sherman–Morrison–Woodbury formula (SMW, see 4.3.1), which is also used when deriving the rank-one update of a quasi-Newton optimization approach.
Proof. Denote \(\mathbf{X}_{[i]}\) and \(\mathbf{y}_{[i]}\) the data derived from \(\mathbf{X}\) and \(\mathbf{y}\), but with the \(i\) observation (\(x_i\), \(y_i\)) removed. We then have the properties that
\[\mathbf{X}_{[i]}^\text{T}\mathbf{X}_{[i]} = \mathbf{X}^\text{T}\mathbf{X}- x_i x_i^\text{T}, \]
and
\[\mathbf{H}_{ii} = x_i^\text{T}(\mathbf{X}^\text{T}\mathbf{X})^{-1} x_i.\]
By the SMW formula, we have
\[(\mathbf{X}_{[i]}^\text{T}\mathbf{X}_{[i]})^{-1} = (\mathbf{X}^\text{T}\mathbf{X})^{-1} + \frac{(\mathbf{X}^\text{T}\mathbf{X})^{-1}x_i x_i^\text{T}(\mathbf{X}^\text{T}\mathbf{X})^{-1}}{ 1 - \mathbf{H}_{ii}}, \]
Further notice that
\[\mathbf{X}_{[i]}^\text{T}\mathbf{y}_{[i]} = \mathbf{X}^\text{T}\mathbf{y}- x_i y_i, \]
we can then reconstruct the fitted parameter when observation \(i\) is removed:
\[\begin{align} \widehat{\boldsymbol{\beta}}_{[i]} =& (\mathbf{X}_{[i]}^\text{T}\mathbf{X}_{[i]})^{-1} \mathbf{X}_{[i]}^\text{T}\mathbf{y}_{[i]} \\ =& \left[ (\mathbf{X}^\text{T}\mathbf{X})^{-1} + \frac{(\mathbf{X}^\text{T}\mathbf{X})^{-1}x_i x_i^\text{T}(\mathbf{X}^\text{T}\mathbf{X})^{-1}}{ 1 - \mathbf{H}_{ii}} \right] (\mathbf{X}^\text{T}\mathbf{y}- x_i y_i)\\ =& (\mathbf{X}^\text{T}\mathbf{X})^{-1} \mathbf{X}^\text{T}\mathbf{y}+ \left[ - (\mathbf{X}^\text{T}\mathbf{X})^{-1} x_i y_i + \frac{(\mathbf{X}^\text{T}\mathbf{X})^{-1}x_i x_i^\text{T}(\mathbf{X}^\text{T}\mathbf{X})^{-1}}{ 1 - \mathbf{H}_{ii}} (\mathbf{X}^\text{T}\mathbf{y}- x_i y_i) \right] \\ =& \widehat{\boldsymbol{\beta}} - \frac{(\mathbf{X}^\text{T}\mathbf{X})^{-1} x_i}{1 - \mathbf{H}_{ii}} \left[ y_i (1 - \mathbf{H}_{ii}) - x_i^\text{T}\widehat{\boldsymbol{\beta}} + \mathbf{H}_{ii} y_i \right]\\ =& \widehat{\boldsymbol{\beta}} - \frac{(\mathbf{X}^\text{T}\mathbf{X})^{-1} x_i}{1 - \mathbf{H}_{ii}} \left( y_i - x_i^\text{T}\widehat{\boldsymbol{\beta}} \right) \end{align}\]
Then the error of the \(i\)th obervation from the leave-one-out model is
\[\begin{align} y _i - \widehat{y}_{[i]} =& y _i - x_i^\text{T}\widehat{\boldsymbol{\beta}}_{[i]} \\ =& y _i - x_i^\text{T}\left[ \widehat{\boldsymbol{\beta}} - \frac{(\mathbf{X}^\text{T}\mathbf{X})^{-1} x_i}{1 - \mathbf{H}_{ii}} \left( y_i - x_i^\text{T}\widehat{\boldsymbol{\beta}} \right) \right]\\ =& y _i - x_i^\text{T}\widehat{\boldsymbol{\beta}} + \frac{x_i^\text{T}(\mathbf{X}^\text{T}\mathbf{X})^{-1} x_i}{1 - \mathbf{H}_{ii}} \left( y_i - x_i^\text{T}\widehat{\boldsymbol{\beta}} \right)\\ =& y _i - x_i^\text{T}\widehat{\boldsymbol{\beta}} + \frac{\mathbf{H}_{ii}}{1 - \mathbf{H}_{ii}} \left( y_i - x_i^\text{T}\widehat{\boldsymbol{\beta}} \right)\\ =& \frac{y_i - x_i^\text{T}\widehat{\boldsymbol{\beta}}}{1 - \mathbf{H}_{ii}} \end{align}\]
This completes the proof.
7.7.1 Generalized cross-validation
The generalized cross-validation (GCV, Golub, Heath, and Wahba (1979)) is a modified version of the leave-one-out CV:
\[\text{GCV}(\lambda) = \frac{\sum_{i=1}^n (y_i - x_i^\text{T}\widehat{\boldsymbol{\beta}}^\text{ridge}_\lambda)}{(n - \text{Trace}(\mathbf{S}_\lambda))}\] where \(\mathbf{S}_\lambda\) is the hat matrix corresponding to the ridge regression:
\[\mathbf{S}_\lambda = \mathbf{X}(\mathbf{X}^\text{T}\mathbf{X}+ \lambda \mathbf{I})^{-1} \mathbf{X}^\text{T}\]
The following plot shows how GCV value changes as a function of \(\lambda\).
# use GCV to select the best lambda
plot(fit$lambda[1:500], fit$GCV[1:500], type = "l", col = "darkorange",
ylab = "GCV", xlab = "Lambda", lwd = 3)
title("Prostate Cancer Data: GCV")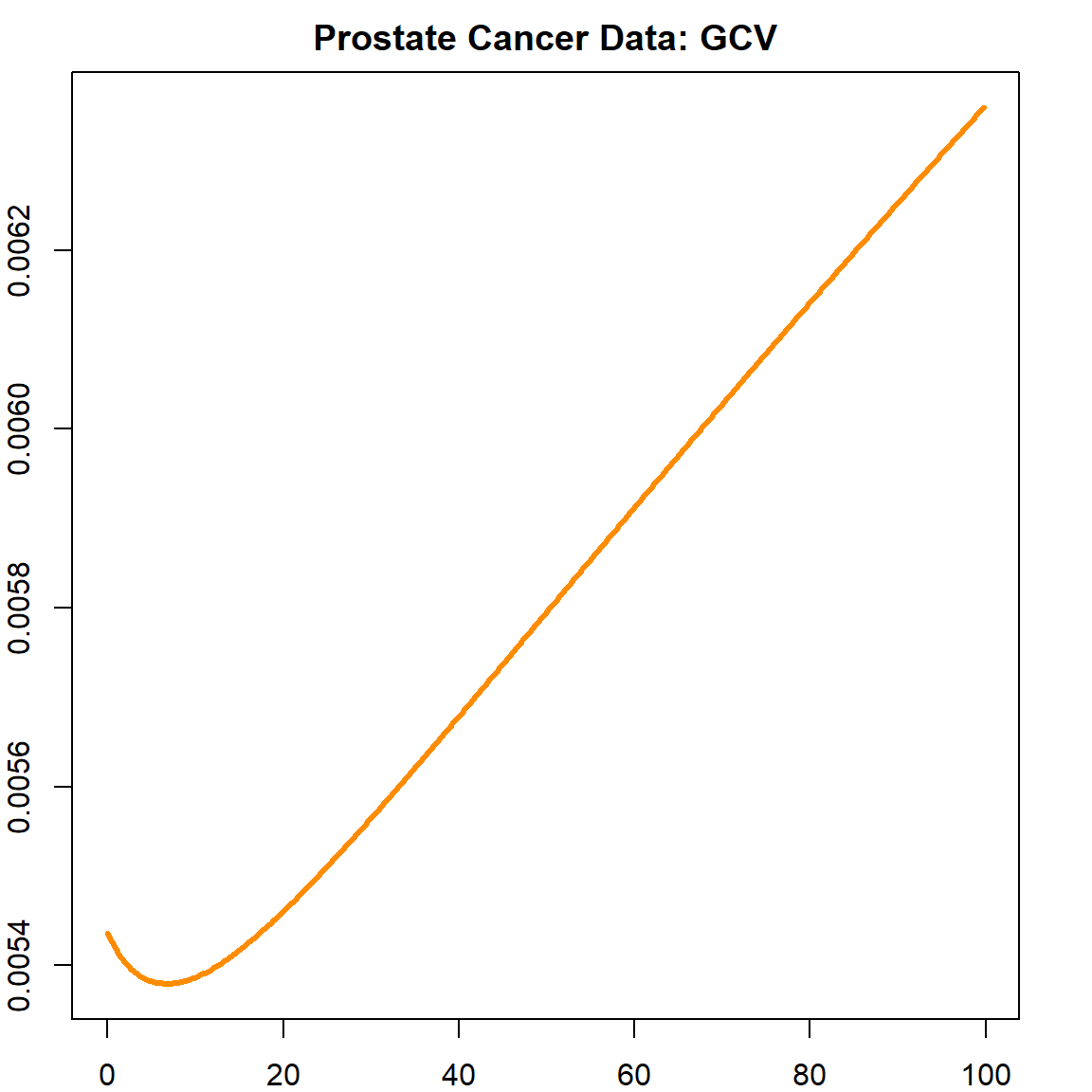
We can select the best \(\lambda\) that produces the smallest GCV.
7.8 The glmnet package
The glmnet package implements the \(k\)-fold cross-validation. To perform a ridge regression with cross-validation, we need to use the cv.glmnet() function with \(alpha = 0\). Here, the \(\alpha\) is a parameter that controls the \(\ell_2\) and \(\ell_1\) (Lasso) penalties. In addition, the lambda values are also automatically selected, on the log-scale.
library(glmnet)
## Loading required package: Matrix
## Loaded glmnet 4.1-10
set.seed(3)
fit2 = cv.glmnet(data.matrix(prostate[, 1:8]), prostate$lpsa, nfolds = 10, alpha = 0)
plot(fit2$glmnet.fit, "lambda")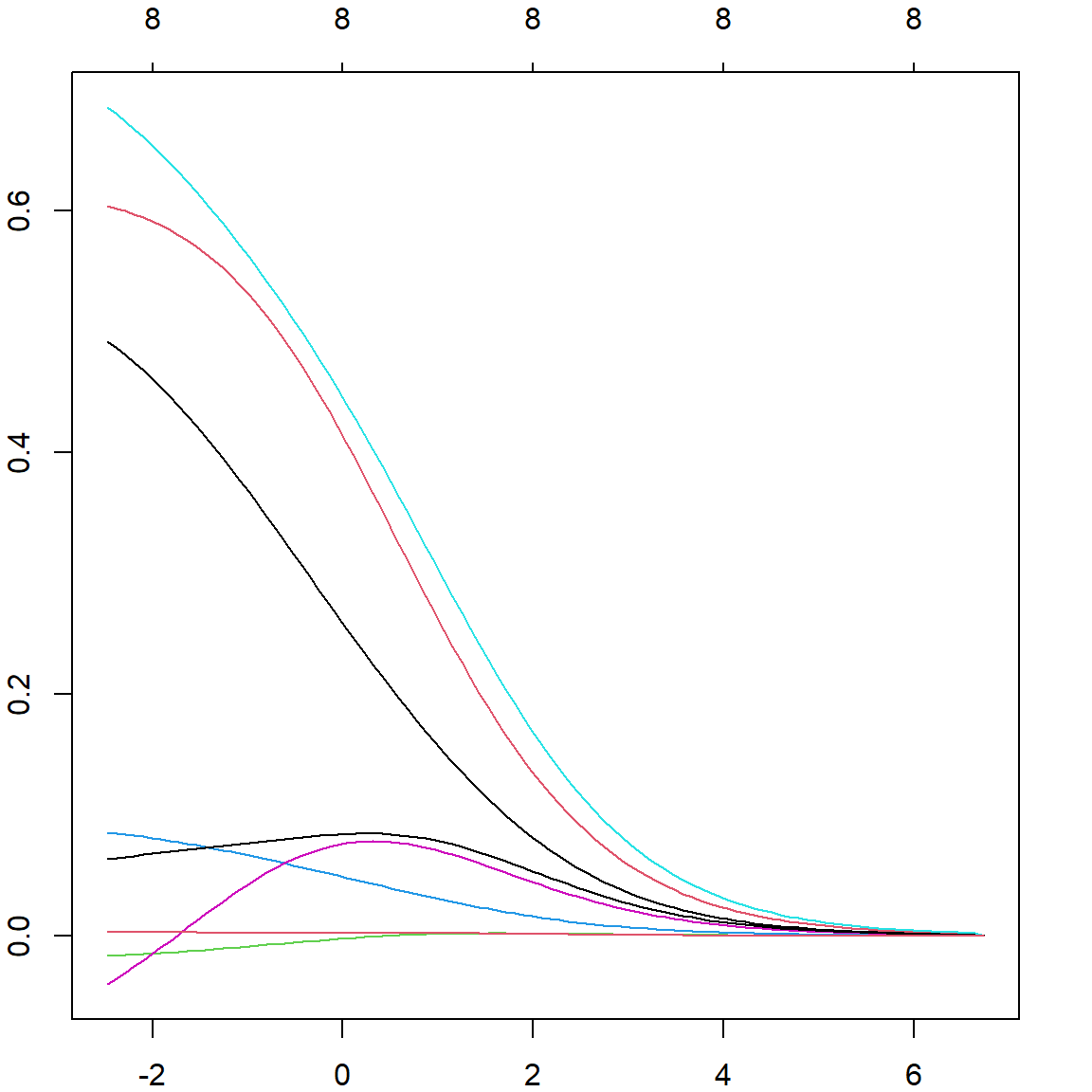
It is useful to plot the cross-validation error against the \(\lambda\) values , then select the corresponding \(\lambda\) with the smallest error. The corresponding coefficient values can be obtained using the s = "lambda.min" option in the coef() function. However, this can still be subject to over-fitting, and sometimes practitioners use s = "lambda.1se" to select a slightly heavier penalized version based on the variations observed from different folds.
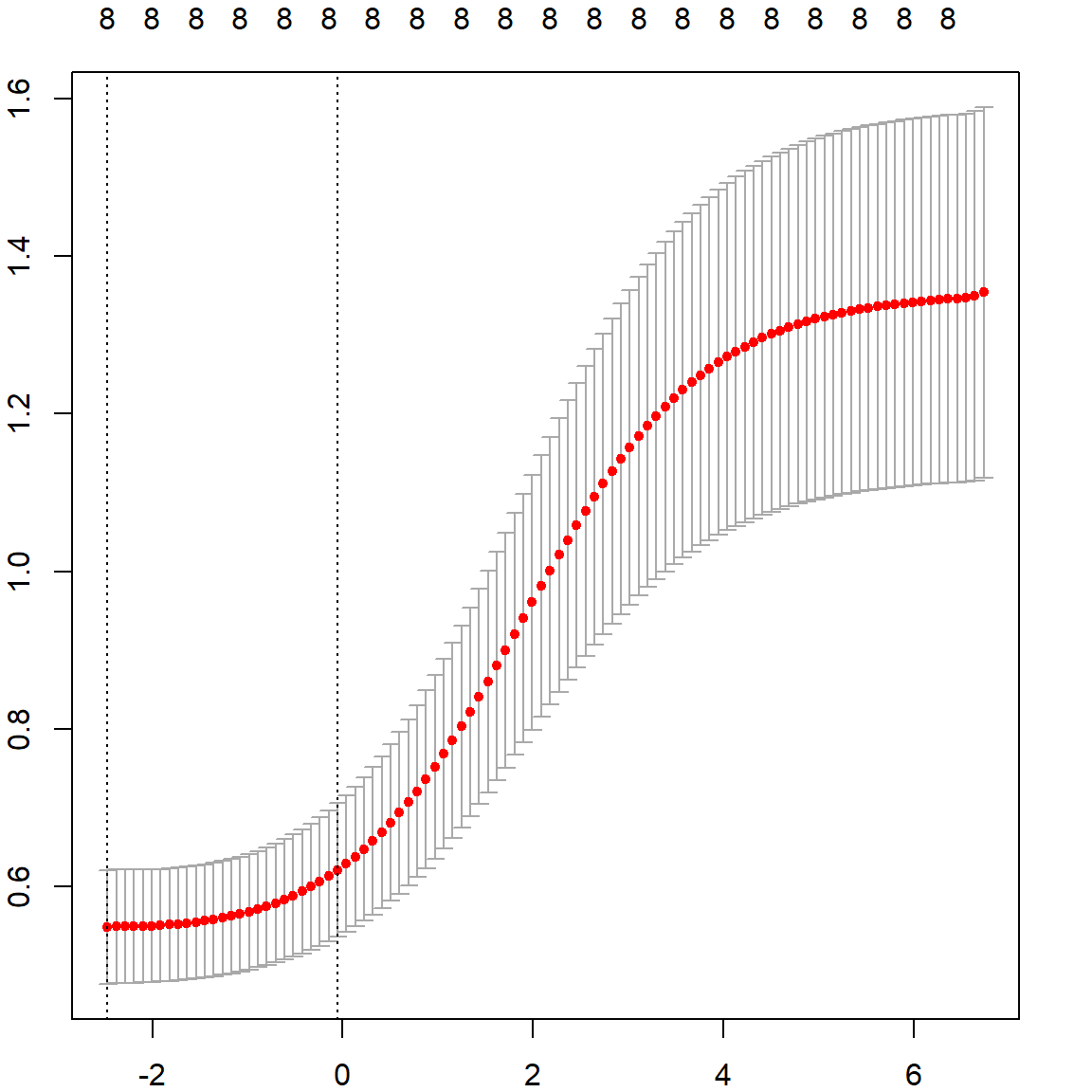
coef(fit2, s = "lambda.min")
## 9 x 1 sparse Matrix of class "dgCMatrix"
## lambda.min
## (Intercept) 0.011566731
## lcavol 0.492211875
## lweight 0.604155671
## age -0.016727236
## lbph 0.085820464
## svi 0.685477646
## lcp -0.039717080
## gleason 0.063806235
## pgg45 0.003411982
coef(fit2, s = "lambda.1se")
## 9 x 1 sparse Matrix of class "dgCMatrix"
## lambda.1se
## (Intercept) 0.035381749
## lcavol 0.264613825
## lweight 0.421408730
## age -0.002555681
## lbph 0.049916919
## svi 0.452500472
## lcp 0.075346975
## gleason 0.083894617
## pgg45 0.0026152357.8.1 Scaling Issue
The glmnet package would using the same strategies for scaling: center and standardize \(\mathbf{X}\) and center \(\mathbf{y}\). A slight difference is that it considers using \(1/(2n)\) as the normalizing factor of the residual sum of squares, but also uses \(\lambda/2 \lVert \boldsymbol{\beta}\rVert_2^2\) as the penalty. This does not affect our formulation since the \(1/2\) cancels out. However, it would slightly affect the Lasso formulation introduced in the next Chapter since the \(\ell_1\) penalty does not apply this \(1/2\) factor. Nonetheless, we can check the (nearly) equivalence between lm.ridge and glmnet():
n = 100
p = 5
X <- as.matrix(scale(matrix(rnorm(n*p), n, p)))
y <- as.matrix(scale(X[, 1] + X[,2]*0.5 + rnorm(n, sd = 0.5)))
lam = 10^seq(-1, 3, 0.1)
fit1 <- lm.ridge(y ~ X, lambda = lam)
fit2 <- glmnet(X, y, alpha = 0, lambda = lam / nrow(X))
# the estimated parameters
par(mfrow=c(1, 2))
matplot(apply(coef(fit1), 2, rev), type = "l", main = "lm.ridge")
matplot(t(as.matrix(coef(fit2))), type = "l", main = "glmnet")