Chapter 8 Lasso
Lasso (Tibshirani 1996) is among the most popular machine learning models. Different from the Ridge regression, its adds \(\ell_1\) penalty on the fitted parameters:
\[\begin{align} \widehat{\boldsymbol{\beta}}^\text{lasso} =& \arg\min_{\boldsymbol{\beta}} (\mathbf{y}- \mathbf{X}\boldsymbol{\beta})^\text{T}(\mathbf{y}- \mathbf{X}\boldsymbol{\beta}) + n \lambda \lVert\boldsymbol{\beta}\rVert_1\\ =& \arg\min_{\boldsymbol{\beta}} \frac{1}{n} \sum_{i=1}^n (y_i - x_i^\text{T}\boldsymbol{\beta})^2 + \lambda \sum_{i=1}^p |\beta_j|, \end{align}\]
The main advantage of adding such a penalty is that small \(\widehat{\beta}_j\) values can be shrunk to zero. This may prevents over-fitting and also improve the interpretability especially when the number of variables is large. We will analyze the Lasso starting with a single variable case, and then discuss the application of coordinate descent algorithm to obtain the solution.
8.1 One-Variable Lasso and Shrinkage
To illustrate how Lasso shrink a parameter estimate to zero, let’s consider an orthogonal design matrix case, i.e., \(\mathbf{X}^\text{T}\mathbf{X}= n \mathbf{I}\), which will eventually reduce to a one-variable problem. Note that the intercept term is not essential because we can always pre-center the observed data \(x_i\) and \(y_i\)s so that they can be recovered after this one variable problem. Our objective function is
\[\frac{1}{n}\lVert \mathbf{y}- \mathbf{X}\boldsymbol{\beta}\rVert^2 + \lambda \lVert\boldsymbol{\beta}\rVert_1\] We are going to relate the solution the OLS solution, which exists in this case because \(\mathbf{X}^\text{T}\mathbf{X}\) is invertible. Hence, we have
\[\begin{align} &\frac{1}{n}\lVert \mathbf{y}- \mathbf{X}\boldsymbol{\beta}\rVert^2 + \lambda \lVert\boldsymbol{\beta}\rVert_1\\ =&\frac{1}{n}\lVert \mathbf{y}- \color{OrangeRed}{\mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols} + \mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols}} - \mathbf{X}\boldsymbol{\beta}\rVert^2 + \lambda \lVert\boldsymbol{\beta}\rVert_1\\ =&\frac{1}{n}\lVert \mathbf{y}- \mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols} \rVert^2 + \frac{1}{n} \lVert \mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols} - \mathbf{X}\boldsymbol{\beta}\rVert^2 + \lambda \lVert\boldsymbol{\beta}\rVert_1 \end{align}\]
The cross-term is zero because the OLS residual term is orthogonal to the columns of \(\mathbf{X}\):
\[\begin{align} &2(\mathbf{y}- \mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols})^\text{T}(\mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols} - \mathbf{X}\boldsymbol{\beta})\\ =& 2\mathbf{r}^\text{T}\mathbf{X}(\widehat{\boldsymbol{\beta}}^\text{ols} - \boldsymbol{\beta})\\ =& 0 \end{align}\]
Then we just need to optimize the part that involves \(\boldsymbol{\beta}\):
\[\begin{align} &\underset{\boldsymbol{\beta}}{\arg\min} \frac{1}{n}\lVert \mathbf{y}- \mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols} \rVert^2 + \frac{1}{n} \lVert \mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols} - \mathbf{X}\boldsymbol{\beta}\rVert^2 + \lambda \lVert\boldsymbol{\beta}\rVert_1\\ =&\underset{\boldsymbol{\beta}}{\arg\min} \frac{1}{n} \lVert \mathbf{X}\widehat{\boldsymbol{\beta}}^\text{ols} - \mathbf{X}\boldsymbol{\beta}\rVert^2 + \lambda \lVert\boldsymbol{\beta}\rVert_1\\ =&\underset{\boldsymbol{\beta}}{\arg\min} \frac{1}{n} (\widehat{\boldsymbol{\beta}}^\text{ols} - \boldsymbol{\beta})^\text{T}\mathbf{X}^\text{T}\mathbf{X}(\widehat{\boldsymbol{\beta}}^\text{ols} - \boldsymbol{\beta}) + \lambda \lVert\boldsymbol{\beta}\rVert_1\\ =&\underset{\boldsymbol{\beta}}{\arg\min} \frac{1}{n} (\widehat{\boldsymbol{\beta}}^\text{ols} - \boldsymbol{\beta})^\text{T}n \mathbf{I}(\widehat{\boldsymbol{\beta}}^\text{ols} - \boldsymbol{\beta}) + \lambda \lVert\boldsymbol{\beta}\rVert_1\\ =&\underset{\boldsymbol{\beta}}{\arg\min} \sum_{j = 1}^p (\widehat{\boldsymbol{\beta}}^\text{ols}_j - \boldsymbol{\beta}_j )^2 + \lambda \sum_j |\boldsymbol{\beta}_j|\\ \end{align}\]
This is a separable problem meaning that we can solve each \(\beta_j\) independently since they do not interfere each other. Then the univariate problem is
\[\underset{\beta}{\arg\min} \,\, (\beta - a)^2 + \lambda |\beta|\] We learned that to solve for an optimizer, we can set the gradient to be zero. However, the function is not everywhere differentiable. Still, we can separate this into two cases: \(\beta > 0\) and \(\beta < 0\). For the positive side, we have
\[\begin{align} 0 =& \frac{\partial}{\partial \beta} \,\, (\beta - a)^2 + \lambda |\beta| = 2 (\beta - a) + \lambda \\ \Longrightarrow \quad \beta =&\, a - \lambda/2 \end{align}\]
However, this will maintain positive only when \(\beta\) is greater than \(a - \lambda/2\). The negative size is similar. And whenever \(\beta\) falls in between, it will be shrunk to zero. Overall, for our previous univariate optimization problem, the solution is
\[\begin{align} \hat\beta_j^\text{lasso} &= \begin{cases} \hat\beta_j^\text{ols} - \lambda/2 & \text{if} \quad \hat\beta_j^\text{ols} > \lambda/2 \\ 0 & \text{if} \quad |\hat\beta_j^\text{ols}| < \lambda/2 \\ \hat\beta_j^\text{ols} + \lambda/2 & \text{if} \quad \hat\beta_j^\text{ols} < -\lambda/2 \\ \end{cases}\\ &= \text{sign}(\hat\beta_j^\text{ols}) \left(|\hat\beta_j^\text{ols}| - \lambda/2 \right)_+ \\ &\doteq \text{SoftTH}(\hat\beta_j^\text{ols}, \lambda) \end{align}\]
This is called a soft-thresholding function. This implies that when \(\lambda\) is large enough, the estimated \(\beta\) parameter of Lasso will be shrunk towards zero. The following animated figure demonstrates how adding an \(\ell_1\) penalty can change the optimizer. The objective function is \(0.5 + (\beta - 1)^2\) and based on our previous analysis, once the penalty is larger than 2, the optimizer would stay at 0.
8.2 Constrained Optimization View
Of course in a multivariate case, this is much more complicated since one variable may affect the optimizer of another. A commonly used alternative interpretation of the Lasso problem is the constrained optimization formulation:
\[\begin{align} \min_{\boldsymbol{\beta}} \,\,& \lVert \mathbf{y}- \mathbf{X}\boldsymbol{\beta}\rVert^2\\ \text{subject to} \,\, & \lVert\boldsymbol{\beta}\rVert_1 \leq t \end{align}\]
We can see from the left penal of the following figure that, the Lasso penalty imposes a constraint with the rhombus, i.e., the solution has to stay within the shaded area. The objective function is shown with the contour, and once the contained area is sufficiently small, some \(\beta\) parameter will be shrunk to exactly zero. On the other hand, the Ridge regression also has a similar interpretation. However, since the constrained areas is a circle, it will never for the estimated parameters to be zero.
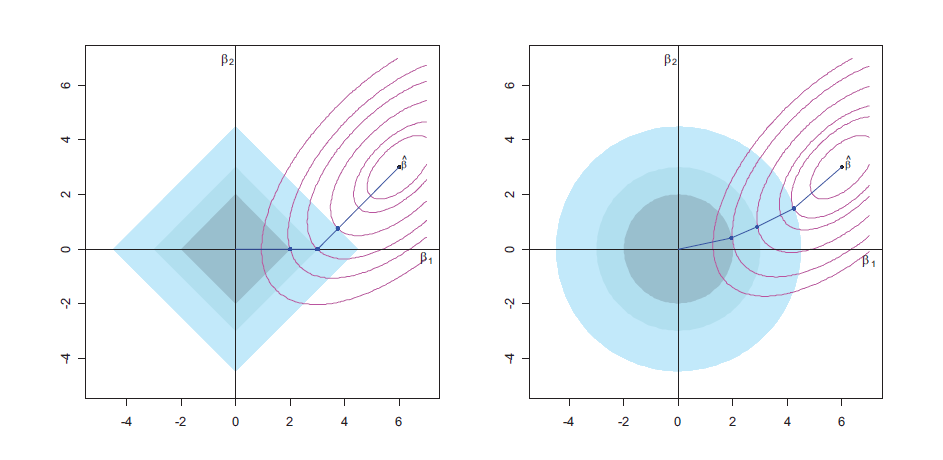 Figure from online sources.
Figure from online sources.
The equivalence of these two forms in a Ridge regression setting can be seen from the Lagrangian and the Karush-Kuhn-Tucker (KKT, (Boyd and Vandenberghe 2004)) conditions. The constrained form can be written as:
\[ \begin{aligned} \min_{\boldsymbol{\beta}} \quad & \frac{1}{2} \|\mathbf{y}- \mathbf{X}\boldsymbol{\beta}\|_2^2 \\ \text{s.t.} \quad & \|\boldsymbol{\beta}\|_2^2 \leq t \end{aligned} \]
The Lagrangian for the constrained form is:
\[ \mathcal{L}(\boldsymbol{\beta}, \alpha) = \frac{1}{2} \|\mathbf{y}- \mathbf{X}\boldsymbol{\beta}\|_2^2 + \alpha \left( \|\boldsymbol{\beta}\|_2^2 - t \right) \]
The KKT conditions are as follows:
Stationarity Conditions:
\[ \nabla_\boldsymbol{\beta}\mathcal{L} = -\mathbf{X}^T(\mathbf{y}- \mathbf{X}\boldsymbol{\beta}) + \alpha \boldsymbol{\beta}= 0 \]
\[ \Rightarrow \boldsymbol{\beta}^* = (\mathbf{X}^T \mathbf{X}+ \alpha I)^{-1} \mathbf{X}^T \mathbf{y} \]
Primal Feasibility:
\[ \|\boldsymbol{\beta}^*\|_2^2 \leq t \]
Dual Feasibility:
\[ \alpha \geq 0 \]
Complementary Slackness:
\[ \alpha (\|\boldsymbol{\beta}^*\|_2^2 - t) = 0 \]
Noticing that from the penalized form, we know that the solution of a Ridge regression is \(\beta = (\mathbf{X}^T \mathbf{X}+ \lambda \mathbf{I})^{-1} \mathbf{X}^T \mathbf{y}\). The penalized and constrained forms are equivalent in that for each value of \(\lambda\) in the penalized form, there exists a corresponding value of \(t\) in the constrained form, such that both yield the same optimal \(\boldsymbol{\beta}\). The KKT conditions play a crucial role in establishing the equivalence. The Primal Feasibility condition ensures that the optimized \(\boldsymbol{\beta}^*\) adheres to the constraint \(\|\boldsymbol{\beta}^*\|_2^2 \leq t\), affirming the legitimacy of the solution within the defined problem space. On the other hand, the Dual Feasibility condition \(\alpha \geq 0\) guarantees that the Lagrange multiplier is non-negative, which is a requisite for the constrained optimization problem to have a dual. Finally, the Complementary Slackness condition \(\alpha (\|\boldsymbol{\beta}^*\|_2^2 - t) = 0\) essentially ties the primal and dual problems together. It indicates that if the constraint \(\|\boldsymbol{\beta}^*\|_2^2 \leq t\) is strictly met (not at the boundary), then \(\alpha\) must be zero; conversely, if \(\alpha > 0\), then the constraint must be “binding,” meaning \(\|\boldsymbol{\beta}^*\|_2^2 = t\). These conditions collectively affirm the equivalence of the penalized and constrained forms by establishing a one-to-one correspondence between their solutions for given values of \(\lambda\) and \(t\).
8.3 The Solution Path
We are interested in getting the fitted model with a given \(\lambda\) value, however, for selecting the tuning parameter, it would be much more stable to obtain the solution on a sequence of \(\lambda\) values. The corresponding \(\boldsymbol{\beta}\) parameter estimates are called the solution path, i.e., the path how parameter changes as \(\lambda\) changes. We have seen an example of this with the Ridge regression. For Lasso, the the solution path has an interpretation as the forward-stagewise regression. This is different than the forward stepwise model we introduced before. A forward stagewise regression works in the following way:
- Start with the Null model (intercept) and choose the best variable out of all \(p\), such that when its parameter grows by a small magnitude \(\epsilon\) (either positive or negative), the RSS reduces the most. Grow the parameter estimate of this variable by \(\epsilon\) and repeat.
The stage-wise regression solution has been shown to give the same solution path as the Lasso, if we start with a sufficiently large \(\lambda\), and gradually reduces it towards zero. This can be done with the least angle regression (lars) package. Note that the lars package introduces another computationally more efficient approach to obtain the same solution, but we will not discuss it in details. We comparing the two approaches (stagewise and stepwise) using the prostate data from the ElemStatLearn package.
library(lars)
library(ElemStatLearn)
data(prostate)
lars.fit = lars(x = data.matrix(prostate[, 1:8]), y = prostate$lpsa,
type = "forward.stagewise")
plot(lars.fit)
lars.fit = lars(x = data.matrix(prostate[, 1:8]), y = prostate$lpsa,
type = "stepwise")
plot(lars.fit)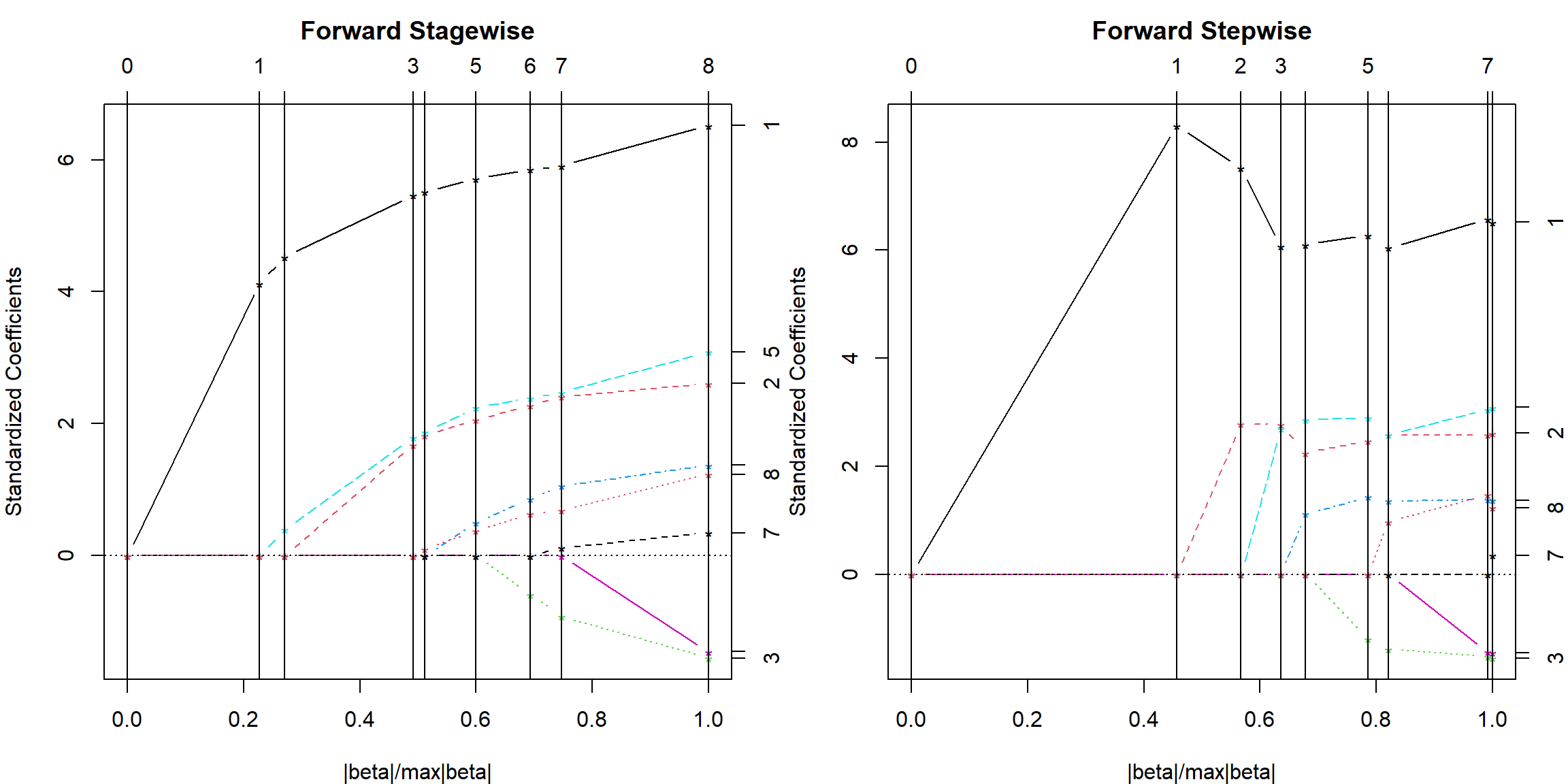
At each vertical line, a new variable enters the model by growing its parameter out of zero. You can relate this to our previous animated graph where as \(\lambda\) decreases, the parameter estimate eventually comes out of zero. However, they may change their grow rate as a new variable comes. This is due to the covariance structure.
8.4 Path-wise Coordinate Descent
The coordinate descent algorithm (J. Friedman, Hastie, and Tibshirani 2010) is probably the most efficient way to solve the Lasso solution up to now. The idea shares similarities with the stage-wise regression. However, with some careful analysis, we can obtain coordinate updates exactly, instead of moving a small step size. And this is done on a decreasing grid of \(\lambda\) values. A pseudo algorithm proceed in the following way:
- Start with a \(\lambda\) value sufficiently large such that all parameter estimates are zero.
- Reduce \(\lambda\) by a fraction, e.g., 0.05, and perform coordinate descent updates:
- For \(j = 1, \ldots p\), update \(\beta_j\) using a one-variable penalized formulation.
- Repeat i) until convergence.
- Record the corresponding \(\widehat{\boldsymbol{\beta}}^\text{lasso}_\lambda\).
- Repeat steps 2) and 3) until \(\lambda\) is sufficiently small or there are already \(n\) nonzero parameters entered into the model. Output \(\widehat{\boldsymbol{\beta}}^\text{lasso}_\lambda\) for all \(\lambda\) values.
The crucial step is then figuring out the explicit formula of the coordinate update. Recall that in a coordinate descent algorithm of OLS at Section 5.8, we update \(\beta_j\) using
\[ \underset{\boldsymbol \beta_j}{\text{argmin}} \,\, \frac{1}{n} ||\mathbf{y}- X_j \beta_j - \mathbf{X}_{(-j)} \boldsymbol{\beta}_{(-j)} ||^2 \] Since this is a one-variable OLS problem, the solution is
\[ \beta_j = \frac{X_j^T \mathbf{r}}{X_j^T X_j} \]
with \(\mathbf{r}= \mathbf{y}- \mathbf{X}_{(-j)} \boldsymbol{\beta}_{(-j)}\). Now, adding the penalty \(|\beta_j|\), we essentially reduces back to the previous example of the single variable lasso problem, where we have the OLS solution. Hence, all we need to do is to apply the soft-thresholding function. The the Lasso coordinate update becomes
\[\beta_j^\text{new} = \text{SoftTH}\left(\frac{X_j^T \mathbf{r}}{X_j^T X_j}, \lambda\right) \]
Incorporate this into the previous algorithm, we can obtain the entire solution path of a Lasso problem. This algorithm is implemented in the glmnet package. We will show an example of it.
8.5 Using the glmnet package
We still use the prostate cancer data prostate data. The dataset contains 8 explanatory variables and one outcome lpsa, the log prostate-specific antigen value. We fit the model using the glmnet package. The tuning parameter can be selected using cross-validation with the cv.glmnet function. You can specify nfolds for the number of folds in the cross-validation. The default is 10. For Lasso, we should use alpha = 1, while alpha = 0 is for Ridge. However, it is the default value that you do not need to specify.
library(glmnet)
set.seed(3)
fit2 = cv.glmnet(data.matrix(prostate[, 1:8]), prostate$lpsa, nfolds = 10, alpha = 1)The left plot demonstrates how \(\lambda\) changes the cross-validation error. There are two vertical lines, which represents lambda.min and lambda.1se respectively. The right plot shows how \(\lambda\) changes the parameter values, with each line representing a variable. The x-axis in the figure is in terms of \(\log(\lambda)\), hence their is a larger penalty to the right. Note that the glmnet package uses \(1/(2n)\) in the loss function instead of \(1/n\), hence the corresponding soft-thresholding function would reduce the magnitude of \(\lambda\) by \(\lambda\) instead of half of it. Moreover, the package will perform scaling before the model fitting, which essentially changes the corresponding one-variable OLS solution. The solution on the original scale will be retrieved once the entire solution path is finished. However, we usually do not need to worry about these computationally issues in practice. The main advantage of Lasso is shown here that the model can be sparse, with some parameter estimates shrunk to exactly 0.

We can obtain the estimated coefficients from the best \(\lambda\) value. Similar to the ridge regression example, there are two popular options, lambda.min and lambda.1se. The first one is the value that minimizes the cross-validation error, the second one is slightly more conservative, which gives larger penalty value with more shrinkage. You can notice that lambda.min contains more nonzero parameters.
coef(fit2, s = "lambda.min")
## 9 x 1 sparse Matrix of class "dgCMatrix"
## lambda.min
## (Intercept) 0.1537694867
## lcavol 0.5071477800
## lweight 0.5455934491
## age -0.0084065349
## lbph 0.0618168146
## svi 0.5899942923
## lcp .
## gleason 0.0009732887
## pgg45 0.0023140828
coef(fit2, s = "lambda.1se")
## 9 x 1 sparse Matrix of class "dgCMatrix"
## lambda.1se
## (Intercept) 0.6435469
## lcavol 0.4553889
## lweight 0.3142829
## age .
## lbph .
## svi 0.3674270
## lcp .
## gleason .
## pgg45 .Prediction can be done using the predict() function.
8.6 Elastic-Net
Lasso may suffer in the case where two variables are strongly correlated. The situation is similar to OLS, however, in Lasso, it would only select one out of the two, instead of letting both parameter estimates to be large. This is not preferred in some practical situations such as genetic studies because expressions of genes from the same pathway may have large correlation, but biologist want to identify all of them instead of just one. The Ridge penalty may help in this case because it naturally considers the correlation structure. Hence the Elastic-Net (Zou and Hastie 2005) penalty has been proposed to address this issue: the data contains many correlated variables and we want to select them together if they are important for prediction. The glmnet package uses the following definition of an Elastic-Net penalty, which is a mixture of \(\ell_1\) and \(\ell_2\) penalties:
\[\lambda \left[ (1 - \alpha)/2 \lVert \boldsymbol{\beta}\rVert_2^2 + \alpha |\boldsymbol{\beta}|_1 \right],\] which involves two tuning parameters. However, in practice, it is very common to simply use \(\alpha = 0.5\).